

Apache NiFi for Enterprise Data Flows: Architecture, Use Cases, and Best Practices
![]()

Complete guide to Apache NiFi for enterprise data flows. Learn architecture, use cases, best practices, and how to run NiFi at scale in production environments.
Apache NiFi has become a foundational component in many modern data infrastructures, moving data between systems, supporting real-time and batch pipelines, and handling complex integrations that would otherwise require heavy custom engineering..
As adoption grows, NiFi evolves from a simple integration tool into a critical infrastructure, powering reporting, operational workflows, and compliance-sensitive processes. At that stage, architecture, scalability, and long-term operability matter more than individual processor settings. So does Apache NiFi flow deployment, how flows move from development into production, and how reliably that process runs at scale.
This blog looks at Apache NiFi from that enterprise perspective, highlighting its structural design, common use cases, operational challenges at scale, and best practices for stable, predictable, and governable production deployments.
What Is Apache NiFi and Why Enterprises Use It
Apache NiFi is an enterprise data integration platform designed for data flow automation, moving data reliably between systems in real-time and batch modes. At its core, it focuses on one problem and does it well, managing how data is collected, routed, transformed, and delivered across diverse environments.
As a real-time data processing platform, NiFi has evolved beyond simple integration into critical enterprise infrastructure, enabling organizations to build resilient data pipeline architecture across complex ecosystems.
Unlike custom scripts or tightly coupled integrations, NiFi provides a visual and declarative way to define data flows. Teams can see how data moves, where it branches, and how failures are handled. That visibility is one of the reasons NiFi is widely adopted in enterprise environments, especially where data pipelines are expected to run continuously and support multiple downstream systems.
Example: How Apache NiFi works in practice
Consider an e-commerce business processing orders from a website, mobile app, and marketplaces. Each order needs to reach multiple systems, order management, inventory, analytics, and sometimes fraud detection.
With Apache NiFi, these steps are defined as a visual data flow. Incoming orders are collected from different sources, routed based on rules, transformed if needed, and delivered to multiple destinations at the same time.
If a system is unavailable, NiFi retries based on processor configuration or routes failed data to a separate path. Teams can see exactly where data is flowing, where it is delayed, and how failures are handled, all from the UI.
In practice, flow-based architecture means observable data movement that runs continuously without fragile scripts or hidden dependencies.
How NiFi Becomes Part of Core Enterprise Infrastructure:
Enterprises use Apache NiFi because it balances flexibility with control. It supports real-time and batch workloads, works across on-premise and cloud environments, and handles a wide range of data formats and protocols. More importantly, it treats data movement as a first-class concern, with built-in capabilities for backpressure, reliable data handling, and complete data provenance tracking for audit and compliance requirements.
As NiFi environments scale and mature, they often grow beyond simple integrations. The platform starts acting as connective tissue between operational systems, analytics platforms, and external services. At that point, NiFi is no longer just moving data. It is shaping how information flows through the business, how quickly changes can be made, and how confidently teams can operate those data pipeline architectures in production.
At this stage, Apache NiFi flow deployment, moving flows from development into test and production environments, becomes as important as the flows themselves.
Effective enterprise data flow management requires understanding these scaling challenges and implementing proper governance before they impact production operations. This is where automated deployment and centralized flow management become critical.
When Apache NiFi reaches this level of importance, it is no longer evaluated as a tool. It is evaluated as part of the enterprise architecture itself. That shift explains why NiFi has moved well beyond niche integration use cases and into the core of modern data platforms.
Why Top Businesses Are Moving to Apache NiFi
Top businesses adopt Apache NiFi because it gives them a reliable, visible, and flexible way to move data across systems at scale, without building fragile custom integrations.
Large enterprises deal with constant data motion. Information flows between operational systems, analytics platforms, external partners, and cloud services, often in real time. As these flows multiply, reliability, visibility, and control matter more than raw throughput.
NiFi mirrors how data actually flows inside complex organizations, across departments, systems, and environments, without forcing a rigid architecture.
- Visibility into how data flows: NiFi gives teams a shared, visual view of how data moves across the organization. This reduces reliance on tribal knowledge and makes it easier to assess impact when changes are introduced.
- Reduced coupling between systems: Producers and consumers do not need tight coordination. NiFi provides configurable retry mechanisms, handles traffic spikes through backpressure, and adapts data in transit, which allows systems to scale independently.
- Data pipeline architecture becomes managed infrastructure: For many enterprises, this is the shift. Data pipelines stop looking like scattered scripts and point integrations and start operating as managed, dependable infrastructure. NiFi’s role as an enterprise data platform extends beyond simple integration to become core infrastructure supporting business operations.
That is why NiFi often ends up at the center of enterprise data ecosystems. It supports growth without forcing a single architecture, and it keeps data moving even as systems, teams, and environments change.
Read more about why industry leaders are choosing Apache NiFi at – Why Businesses are Choosing Apache NiFi for Real-Time Data Processing
To see how this plays out in the real world, let’s look at a couple of organizations running NiFi at massive scale, moving billions of events and powering critical data pipelines every day.
NiFi Powering Enterprise Data: Real Example
Micron
Micron, a global semiconductor manufacturer, uses Apache NiFi to collect manufacturing data from factories all over the world and feed it into a centralized global data warehouse. Every sensor reading, production log, and quality metric flows through NiFi, which then consolidates the data and exposes it through data marts for analysts, data scientists, and business teams.
For the really heavy-duty transformations, NiFi works hand-in-hand with Spark jobs running on Hadoop clusters, using the Site-to-Site protocol to move massive volumes of data efficiently. Automation is built in. NiFi’s REST API helps Micron manage flow deployment at scale, spinning up and monitoring new ingestion pipelines without manual intervention. This is Apache NiFi deployment automation applied at a global manufacturing level.
In short, NiFi doesn’t just move data for Micron. It powers real-time insights, drives operational decisions, and scales effortlessly across a truly global footprint.
For teams managing NiFi at similar scale, see how enterprises are solving Apache NiFi flow deployment challenges across environments with Data Flow Manager, explore Apache NiFi’s real-world use cases.
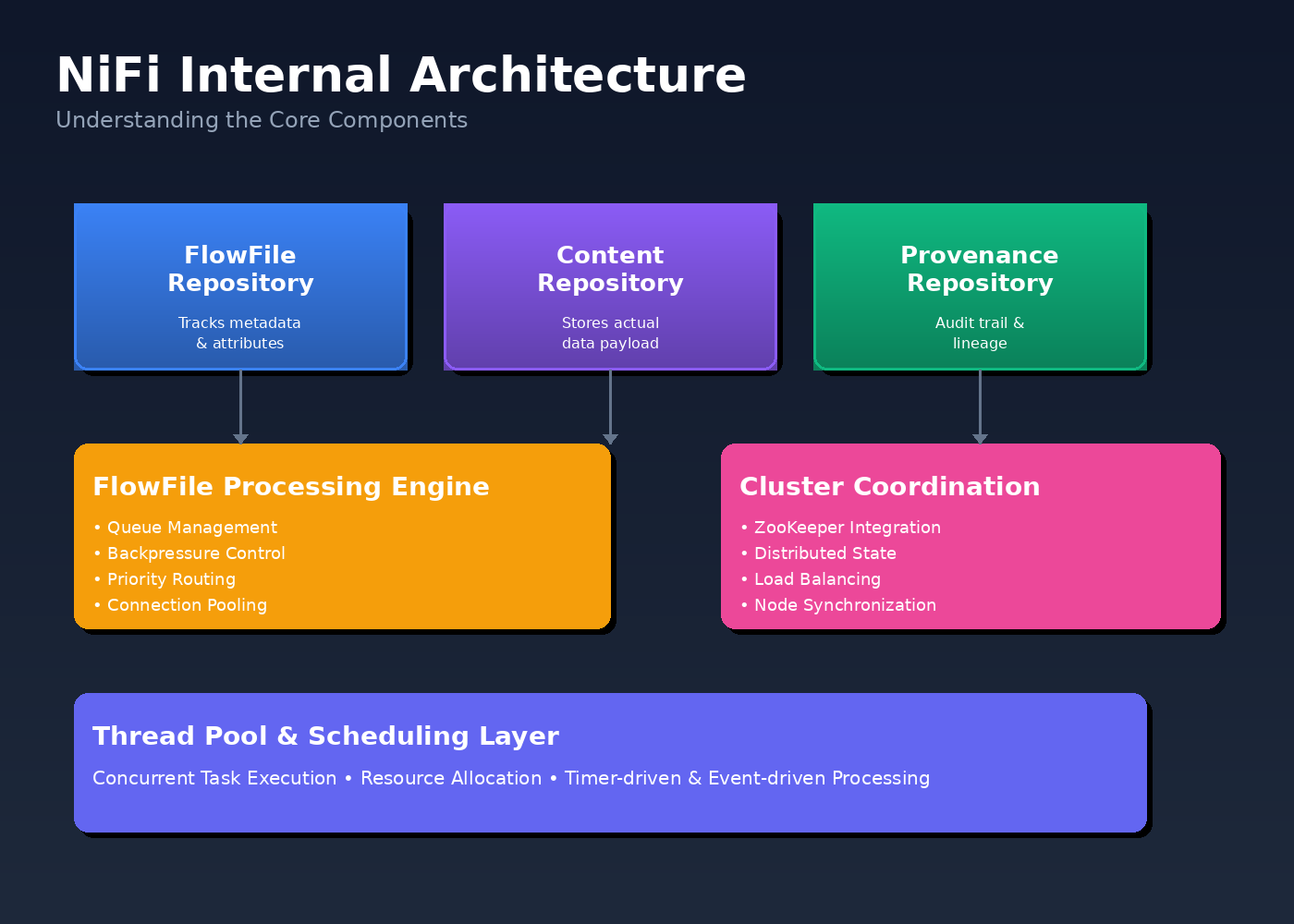
Apache NiFi Architecture: How NiFi Works at Enterprise Scale
Most teams understand NiFi at the processor level. The real challenges show up when NiFi runs continuously, under load, across environments. This section explains that behavior using a simple but realistic example.
A Simple Enterprise Scenario
Assume this flow:
Source
Orders stream in from an API at ~10,000 records per minute.
Processing
- Validate schema
- Enrich with customer
- Route high-value orders to a priority system
Destination
- Write to a data lake
- Push selected events to a downstream service
This flow looks straightforward on the canvas. Operationally, here is what is actually happening.
What NiFi Is Doing Behind the Scenes
FlowFiles in Practice
Each order becomes a FlowFile. Even if each order is only a few KB, NiFi is tracking thousands of FlowFiles every minute. Understanding FlowFile processing and the role of data provenance is critical for enterprise deployments.
If enrichment slows down, FlowFiles do not disappear. They queue up, consume heap, write metadata to disk, and increase lineage tracking overhead. This is why FlowFile count often becomes a scaling constraint, especially in high-throughput environments.
Queues as Pressure Points
The connection between validation and enrichment starts filling up. Backpressure kicks in at the connection level, not at the source.
Result:
- The API ingestion processor slows or pauses
- Upstream systems see delayed acknowledgements
- The issue looks like a source problem, but it is actually downstream imbalance
Repositories Under Load
Every state change is written to the FlowFile repository. Every payload write hits the Content repository. Every hop generates provenance events.
If these repositories share disks or are under-provisioned, latency increases across the entire flow. Processors look healthy, but throughput drops.
This is why disk layout and repository isolation matter more than adding CPU.
Threading Reality Check
A common reaction is to increase concurrent tasks on the enrichment processor.
What actually happens:
- More threads compete for the same disks
- Repository write latency increases
- Overall throughput stays flat or drops
NiFi performance depends on balanced scheduling aligned with available CPU, memory, and disk I/O, rather than blindly increasing parallelism.
Cluster Behavior in the Same Example
In a 3-node cluster:
- Each node independently processes a subset of orders
- ZooKeeper coordinates flow state, not data movement
- If one node has slower disk I/O, queues grow unevenly
From the UI, the flow looks fine. Operationally, one node becomes the silent bottleneck.
Why Teams Struggle Without Architectural Clarity
When this flow degrades, teams often:
- Restart processors
- Add more threads
- Add more nodes
None of these fix the root cause if the issue is queue pressure, repository contention, or uneven node performance.
Understanding this architecture is the difference between tuning NiFi and chasing symptoms.
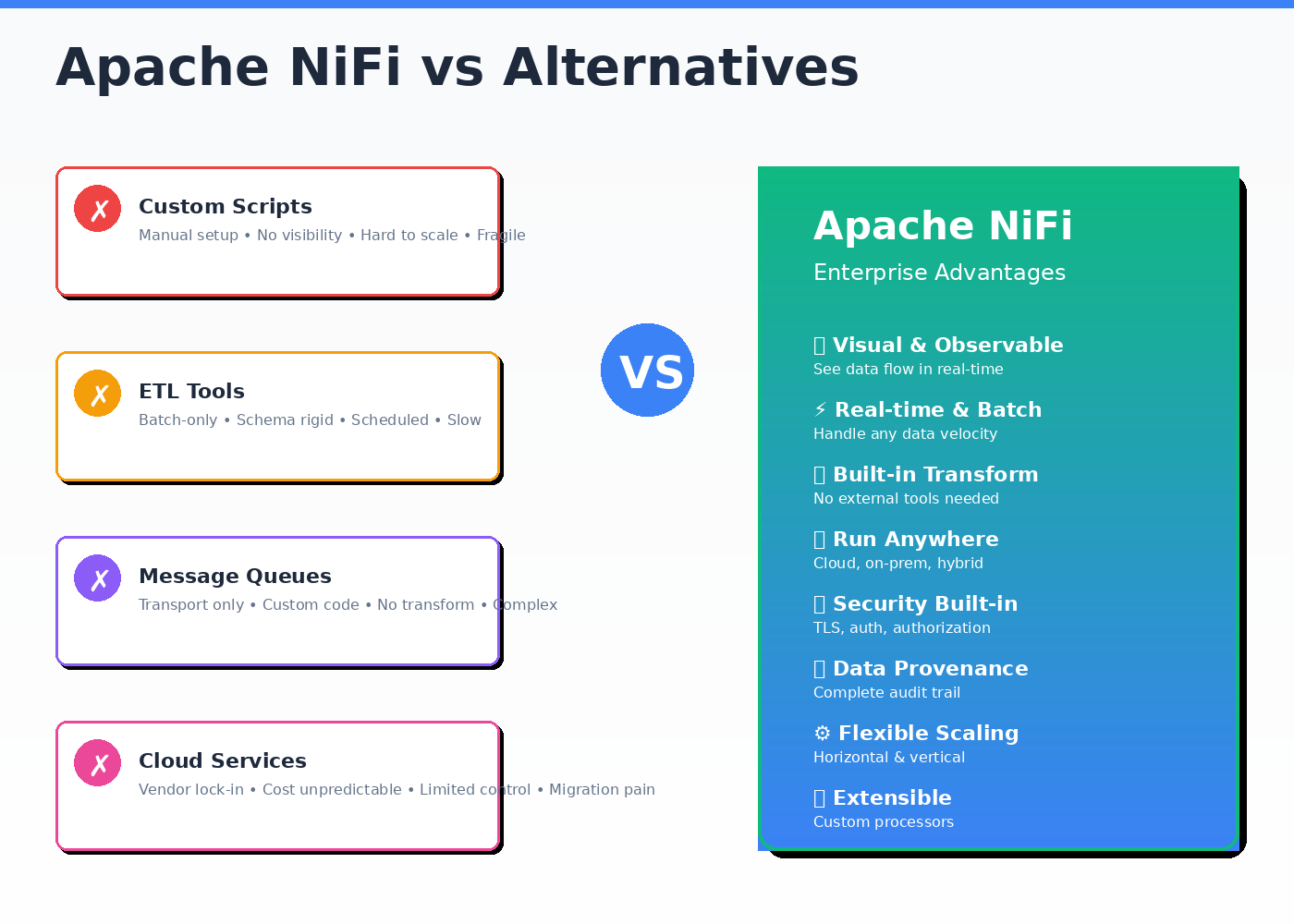
Apache NiFi vs Common Data Integration Alternatives
When teams evaluate Apache NiFi, they start with evaluating Apache NiFi use cases, Apache NiFi best practices, NiFi architecture and how it fits in their system. The real decision is whether NiFi is the right class of tool for the problem at hand.
This section clarifies where NiFi fits and where it does not.
Apache NiFi vs Custom Scripts and Cron Jobs
You might start moving data with scripts or scheduled jobs because it seems simple. Each script does one task: extract from system A, transform, load into system B. It works when flows are small, schedules are predictable, and the team is tiny.
But as data volume grows, dependencies multiply, and teams expand, scripts quickly become fragile. One failed step can cascade downstream, changes are hard to track, visibility is minimal, and scaling is painful, adding a new system often means writing another brittle script.
How NiFi differs
NiFi replaces invisible logic with explicit flows. Data movement, retries, transformations, and routing rules are visible and managed centrally.
Outcome
- Fewer hidden dependencies
- Faster onboarding for new engineers
- Operational issues are observable, not buried in logs
NiFi becomes valuable when pipelines need to be understood and modified by more than one person.
NiFi vs Traditional ETL Tools
Problem teams face
Traditional ETL tools are batch-oriented and assume stable schemas and predictable schedules.
How NiFi differs
NiFi supports event-driven and near real-time data movement. It can handle variable throughput and evolving data formats when flows are designed with appropriate processors and schema management patterns.
Outcome
- Better fit for near real-time ingestion
- Fewer brittle batch windows
- Easier handling of mixed data sources
NiFi is chosen when data arrival is continuous, not scheduled.
Apache NiFi vs Message Queues and Streaming Platforms
Problem teams face
Message brokers excel at transport but push transformation, routing, and error handling into custom code.
How NiFi differs
NiFi combines transport, transformation, and routing in one managed layer, with built-in backpressure and retries.
Outcome
- Less glue code
- Centralized flow logic
- Clear ownership of data movement rules
NiFi complements messaging systems, it does not replace them.
Apache NiFi vs Managed Cloud Integration Services
Problem teams face
Managed services reduce setup effort but limit control over flow behavior, cost predictability, and deployment flexibility.
How NiFi differs
NiFi runs anywhere, on-prem, cloud, or hybrid, with full control over configuration and scaling decisions.
Outcome
- No vendor lock-in
- Predictable operational costs
- Consistent behavior across environments
NiFi is preferred when portability and control matter more than convenience.
Common Enterprise Use Cases for Apache NiFi
Apache NiFi use cases span across industries, from manufacturing to healthcare, wherever enterprise data integration is critical. While implementations differ by industry and scale, several use cases appear consistently across organizations.
These real-world Apache NiFi use cases demonstrate the platform’s versatility across enterprise environments. Organizations leverage NiFi for everything from IoT data ingestion to compliance-driven data lineage tracking. The following scenarios show why NiFi has become essential infrastructure rather than just another integration tool.
These use cases explain why NiFi often becomes a central component of enterprise data platforms rather than a point integration tool.
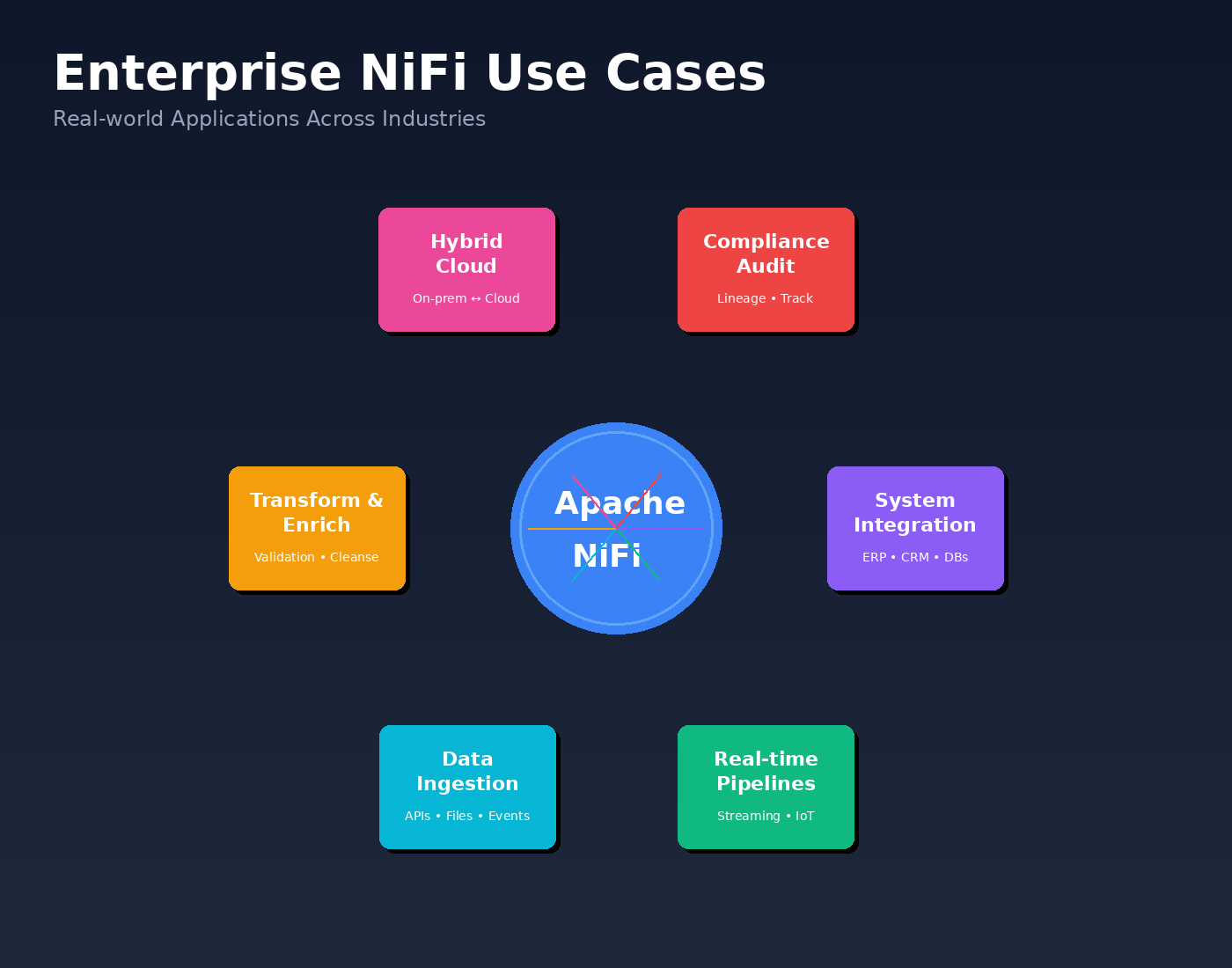
System-to-system data integration
Enterprises use NiFi to connect operational systems such as ERPs, CRMs, databases, and third-party services. NiFi manages data ingestion, routing, and transformation while handling retries and failures automatically. This reduces the need for custom integration code and simplifies long-term maintenance.
Real-time and near real-time data pipelines
Many organizations rely on NiFi to move streaming or event-driven data into analytics platforms, data lakes, and monitoring systems. NiFi supports continuous data flows with backpressure, retry mechanisms, and persistent state management, which is critical when downstream systems have varying performance characteristics.
Data ingestion from external sources
NiFi is commonly used to ingest data from APIs, files, IoT devices, and partner systems. It supports a wide range of protocols and formats, allowing enterprises to standardize ingestion without forcing external sources to conform to a single interface.
Data transformation and enrichment
Before data reaches analytics or operational systems, it often needs validation, enrichment, or normalization. NiFi handles these transformations inline, making data ready for downstream consumption without introducing separate processing layers.
Hybrid and multi-environment data movement
Enterprises running a mix of on-premise systems and cloud services use NiFi to bridge environments. NiFi enables secure, controlled data movement across network boundaries while maintaining visibility and traceability.
Compliance, audit, and data lineage use cases
For regulated industries, NiFi’s built-in data provenance provides a detailed record of how data moves and changes over time. This supports audit requirements, troubleshooting, and confidence in data handling processes.
These scenarios highlight NiFi’s core capabilities.
For a look at how enterprises are applying NiFi in real-world, industry-specific contexts; from smart agriculture to healthcare monitoring, check out this detailed guide:
Apache NiFi Best Practices for Production Deployments
Following Apache NiFi best practices is essential for stable, scalable production operations. These production best practices come from organizations running NiFi at enterprise scale, managing thousands of flows and processing billions of events daily.
Running Apache NiFi in production is less about individual processor configuration and more about operational discipline. Enterprises that rely on NiFi successfully tend to focus on consistency, visibility, and control rather than ad hoc optimization.
The following practices show up repeatedly in stable, long-running NiFi environments.
Treat flows as deployable assets
Production flows should be versioned, reviewed, and promoted through environments in a controlled way. Treating Apache NiFi flow deployment as a formal process, not a manual copy-paste exercise, is what separates teams that scale confidently from those that don’t. Changes made directly in production increase risk and make troubleshooting harder over time.
See how teams implement this in practice: NiFi Data Flow Versioning Best Practices
Separate environments clearly
Development, testing, and production environments should be isolated, with clear promotion paths between them ideally enforced through Apache NiFi deployment automation rather than manual exports and imports. This reduces surprises when flows move to production and helps teams validate behavior before changes go live.
Use parameterization instead of hardcoding
Environment-specific values such as endpoints, credentials, and thresholds should be externalized. Parameterization improves portability and reduces configuration drift between environments.

Design flows for failure, not the happy path
Production flows should expect downstream systems to be slow or unavailable. Using backpressure, retries, and failure paths consistently prevents small issues from cascading into larger outages.
Monitor flow health, not just node health
CPU and memory metrics alone do not tell the full story. Teams should track queue growth, processing latency, and error rates to understand whether data is moving as expected.
Control access and change permissions
As more teams use NiFi, access control becomes critical. Limiting who can modify flows and who can deploy changes helps maintain stability and accountability.
Document flow intent and ownership
Flows should be understandable by someone other than the original author. Clear naming, annotations, and ownership documentation reduce dependency on individuals and speed up incident response.
These practices do not require advanced customization or heavy tooling. They require consistency and agreement across teams.
Organizations that apply them early find it easier to scale NiFi as usage grows. Those that adopt them later often do so in response to incidents, delays, or loss of confidence in production pipelines.
Apache NiFi Scaling Challenges at Enterprise Level
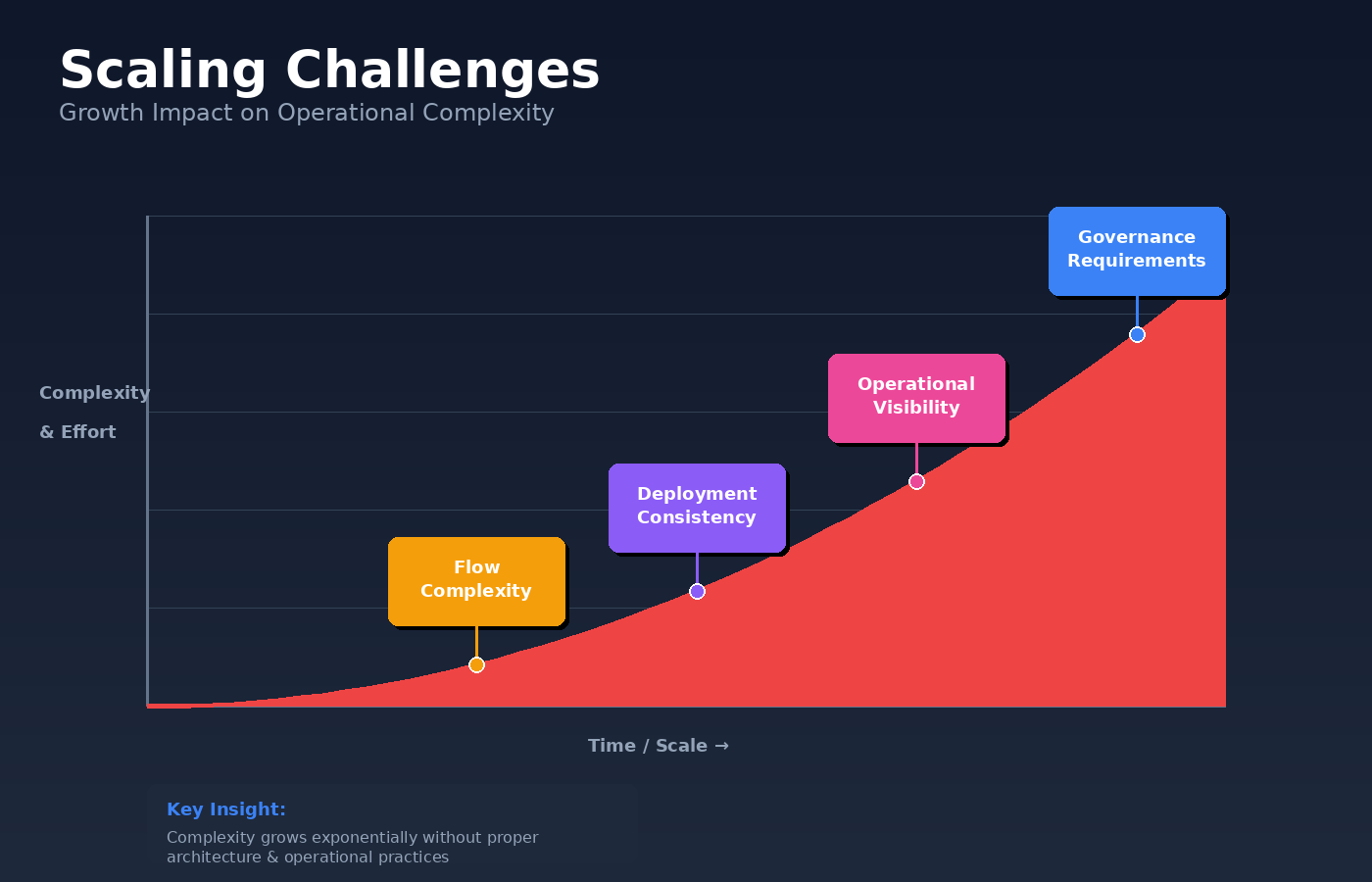
Apache NiFi works well in production when flows are few, teams are small, and changes are infrequent. The best practices outlined earlier are usually enough to keep things stable.
As adoption grows, the operating context changes.
NiFi starts supporting multiple teams, business units, and critical workflows. Environments multiply. Deployments happen more often. At this stage, the challenge is no longer how NiFi works, but how it is managed across the organization.
Growth in number and complexity of flows
What began as a manageable set of pipelines expands into dozens or hundreds of flows. Understanding dependencies, ownership, and impact becomes harder, even with good documentation and naming conventions.
Deployment consistency across environments
Manual or semi-manual promotion of flows increases the chance of configuration drift. Small differences between development, test, and production environments can lead to unexpected behavior after deployment.
See how enterprises handle this with Data Flow Manager →
Limited visibility at an operational level
While NiFi provides strong visibility within a single instance, enterprises often need a broader view. Questions about what changed, when it changed, and where it is running become harder to answer as environments scale.
Slower troubleshooting and recovery
When something breaks, the blast radius is larger. A single delayed or failed flow can affect reporting, customer-facing systems, or downstream automation. Tracing issues across complex flows and multiple integrations takes more time.
Increased governance and audit expectations
As NiFi supports revenue, compliance, or customer data, expectations around change control, traceability, and access restrictions increase. Informal processes that worked earlier begin to feel risky.
Read how a leading bank solved this: NiFi Flow Auditability and Compliance with Data Flow Manager
These challenges rarely stem from NiFi’s core design. They stem from how it is operated at scale. They reflect a shift in how critical the platform has become.
At this stage, organizations start looking for ways to simplify deployments, improve visibility, and bring more structure to how NiFi is operated at scale, without losing the flexibility that made it valuable in the first place.
Bonus Tip: Simplifying Apache NiFi Flow Operations at Scale
As NiFi environments grow, many teams reach a point where good practices alone are not enough. Standardization, validation, and visibility still require manual effort, coordination, and experience.
Some organizations address this by adding a lightweight operational layer on top of Apache NiFi.
Data Flow Manager (DFM) was built for teams that treat NiFi as production infrastructure, not an experimental integration tool. It helps simplify how flows are validated, deployed, and tracked across environments, without changing how NiFi itself works.
Teams use DFM to:
- Run sanity checks and validations before flows reach production
- Standardize flow deployment across development, test, and production
- Track changes and deployments across environments
- Reduce manual effort during promotion and rollback
DFM does not replace Apache NiFi or alter its execution model. It focuses on the operational gaps that appear as NiFi usage grows, especially around flow deployment and governance.
For organizations where NiFi has become critical infrastructure, this kind of operational support such as data flow automation can reduce risk and improve confidence without adding unnecessary complexity.
Read customer success stories →
If you want to understand how teams use DFM alongside Apache NiFi, evaluating operational tooling in the context of your own deployment model is more useful than reviewing feature lists in isolation.
See how Data Flow Manager simplifies Apache NiFi flow deployment and accelerates production operations. Book a free demo or check our FAQs to learn how DFM fits into your NiFi environment.
Conclusion
Apache NiFi earns its place in enterprise data platforms because it treats data movement as a system, not a side task. It brings structure to integration work that often grows organically and invisibly, and it does so in a way teams can actually observe, reason about, and govern over time.
For many organizations, NiFi starts as a practical solution to move data between systems. As usage expands, it becomes part of how the business operates, how changes are introduced, how failures are handled, and how trust in data is maintained. That shift makes architecture decisions, operational discipline, and long-term maintainability far more important than individual processors or flow designs.
When designed deliberately, Apache NiFi enables reliable, scalable data movement across distributed environments. Used without clear standards and operational guardrails, it can also become complex to manage as environments grow. The difference is rarely the tool itself. It is how deliberately it is designed, operated, and evolved.
If Apache NiFi is already part of your enterprise data platform, or you are considering it for enterprise-scale data movement, the goal is not to add more flows. The goal is to make data movement predictable, observable, data flow automation, as the .
And that is where informed architectural choices and mature operational practices matter most.
People Also Ask
Q: What is Apache NiFi used for?
A: Apache NiFi is used for enterprise data integration, automating data flows between systems in real-time. Common use cases include system-to-system integration, IoT data ingestion, real-time data pipelines, and compliance-driven data lineage tracking.
Q: Is Apache NiFi an ETL tool?
A: Apache NiFi is more than a traditional ETL tool. While it can perform extract, transform, and load operations, it specializes in real-time data flow management and supports both batch and streaming data processing.
Q: How does NiFi architecture work?
A: NiFi architecture consists of three main repositories (FlowFile, Content, and Provenance), a processing engine that manages queues and backpressure, and a cluster coordination layer using ZooKeeper for distributed deployments.
![]()
