

Building a Customer Support RAG Pipeline in Apache NiFi 2.x Using Agentic AI
![]()

As enterprises scale, customer support teams struggle to manage thousands of Jira tickets, product manuals, internal troubleshooting notes, runbooks, and engineering documents. Finding accurate information quickly becomes challenging, even for experienced support engineers.
Retrieval-Augmented Generation (RAG) solves this by combining internal knowledge with the reasoning capabilities of LLMs, delivering precise, context-rich answers instantly.
With its modern flow engine, robust REST integrations, and flexible scripting, Apache NiFi 2.x is one of the most powerful platforms to orchestrate end-to-end RAG pipelines.
In this blog, we’ll walk through how to build a Customer Support RAG Pipeline using Jira as the primary data source, and how Data Flow Manager (DFM) intelligently automates the entire lifecycle using its Agentic AI capabilities.
Why RAG for Customer Support?
Support teams deal with an ever-growing pool of information – Jira tickets, engineering notes, configuration guides, product manuals, troubleshooting logs, and years of historical fixes.
But all of this knowledge is scattered across Jira, Confluence, PDFs, shared drives, and internal portals, making it difficult to find the right answer when a customer is waiting.
Support engineers typically need quick access to:
- Recurring or high-volume issues
- Known bugs, patches, and fixes
- Past Jira resolutions
- Setup and configuration instructions
- Historical logs and incident reports
- Internal engineering notes and tribal knowledge
This fragmentation slows down investigation, increases dependency on SMEs, and leads to inconsistent responses.
RAG changes the game by:
- Retrieving the most relevant historical tickets and documents.
- Enriching them with related internal knowledge.
- Grounding the information with LLM reasoning.
- Generating accurate, context-aware answers instantly.
The outcome:
Faster ticket resolution, reduced L1/L2 effort, fewer escalations, and highly consistent support quality, powered by real organizational knowledge, not guesswork.
Architecture Overview
A Customer Support RAG system unifies scattered support knowledge and transforms it into an intelligent, searchable, and automated resolution engine. Apache NiFi 2.x acts as the backbone, coordinating ingestion, processing, vectorization, and LLM-powered response generation.
Data Sources
The pipeline consolidates all critical support intelligence:
- Jira Tickets – issues, comments, resolutions, and historical fixes.
- Product Documentation – PDFs, HTML manuals, release notes.
- Troubleshooting Guides – runbooks, SOPs, diagnostic workflows.
- Engineering Notes & FAQs – internal insights and undocumented knowledge.
NiFi brings these diverse sources into a unified processing stream.
Core Pipeline Stages
The end-to-end RAG workflow is built through a clean, modular data flow:
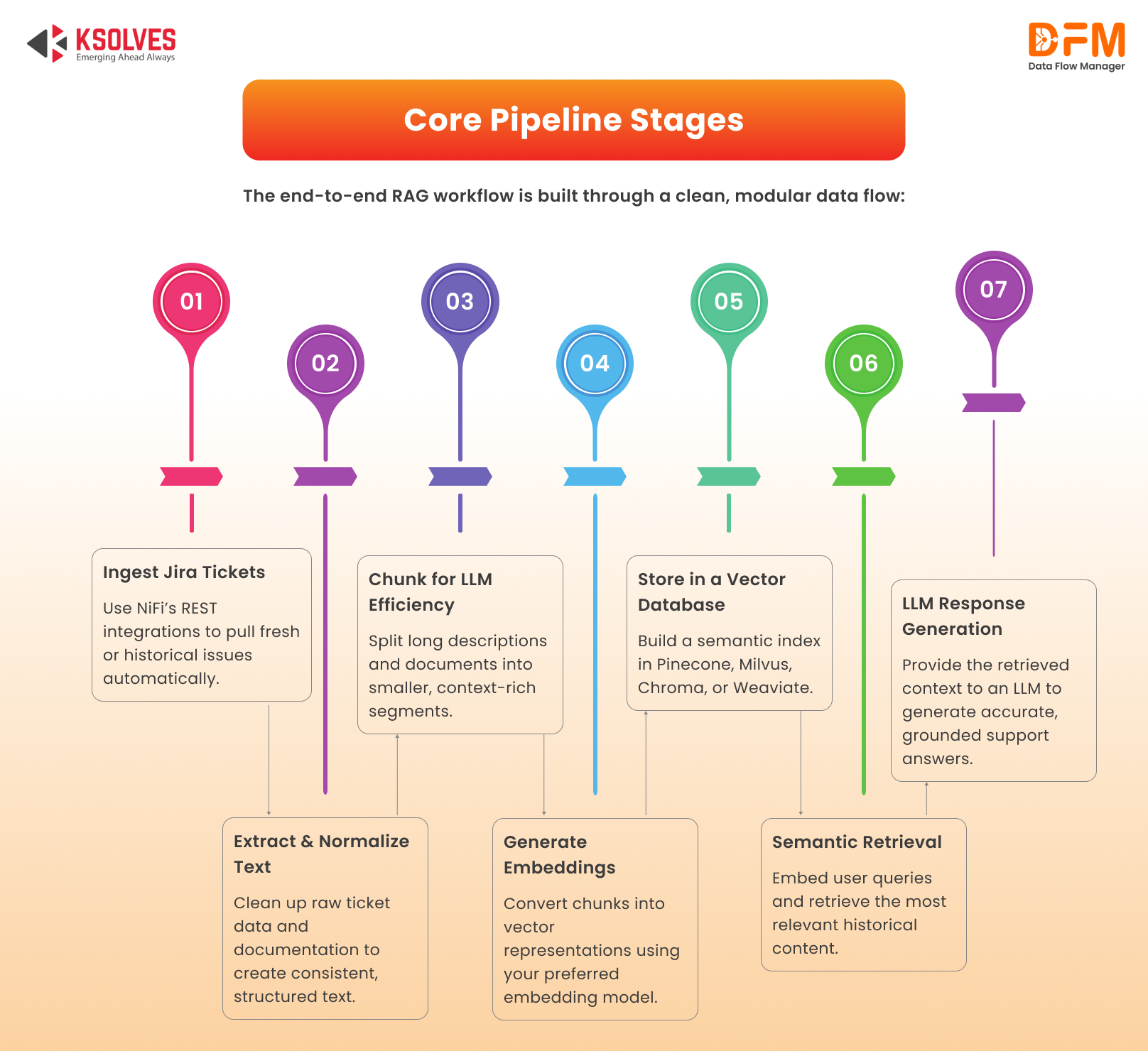
1. Ingesting Jira Tickets Using NiFi 2.x
The first step in any Customer Support RAG pipeline is bringing Jira ticket data into your flow. Apache NiFi 2.x makes this seamless with its modern REST capabilities, native JSON handling, and flexible orchestration.
NiFi connects directly to Jira’s REST APIs, allowing you to pull both historical and real-time ticket updates without custom code. Whether you’re capturing resolved issues, new tickets, or periodic updates, NiFi ensures your RAG knowledge base stays fresh.
Flow:
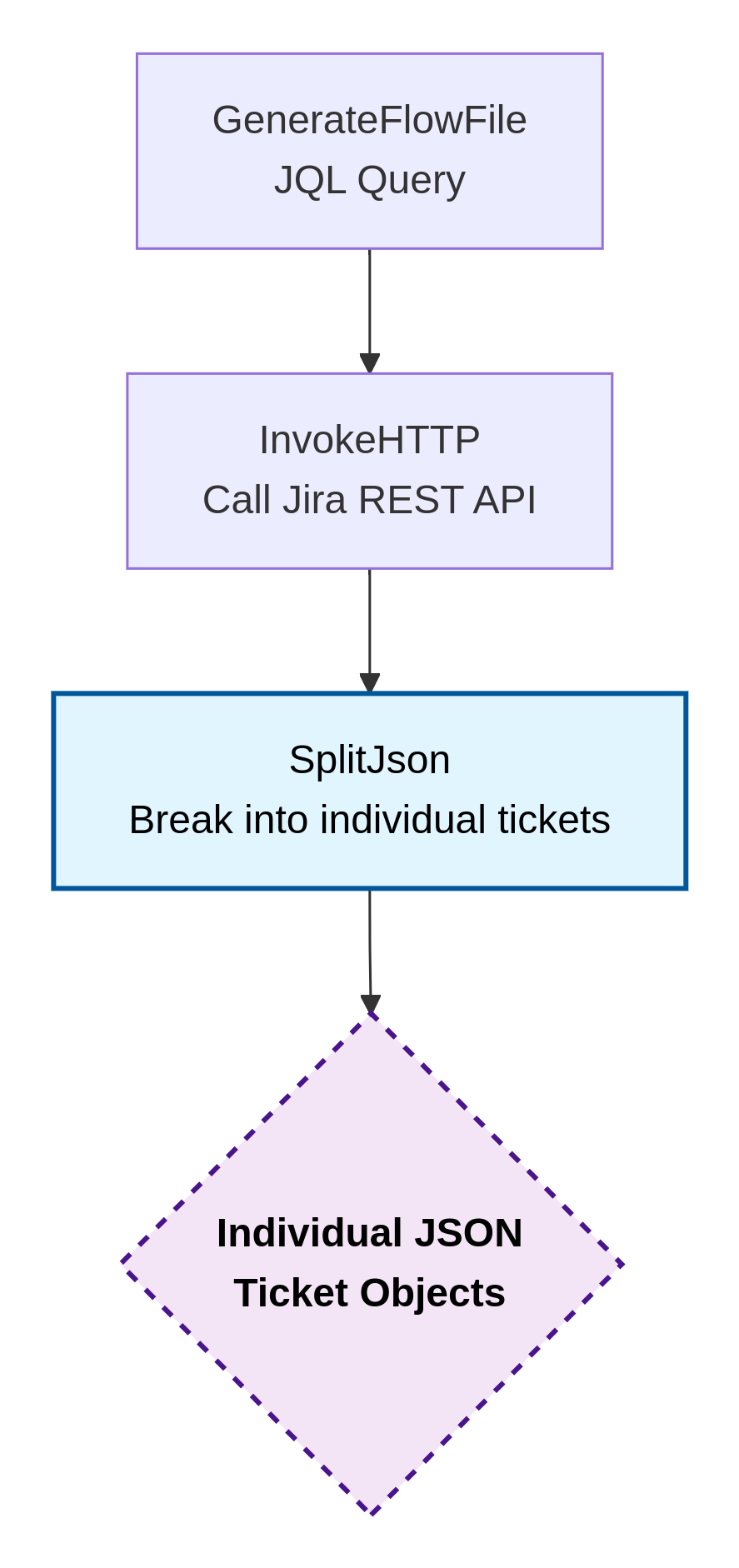

By the end of this stage, each Jira issue becomes a neatly packaged, independently processed flow file, ready for text extraction, chunking, embedding, and storage in your RAG system.
2. Extracting and Normalizing Text
Once Jira issues are ingested, the next challenge is converting raw ticket data into clean, structured text suitable for embeddings. Jira fields often contain mixed formatting, HTML tags, long comment threads, and inconsistent structures.
NiFi 2.x streamlines this entire process with its native JSON capabilities and flexible transformation tools.
What Needs to Be Extracted?
Every Jira ticket typically includes several key text-rich fields:
- Summary – a quick, high-level description.
- Description – detailed problem statement.
- Resolution – how the issue was solved.
- Comments – back-and-forth conversations and clarifications.
These fields contain invaluable support intelligence, but not in a format that LLMs can use as-is.
How NiFi Handles It:

Each ticket is transformed into a structured, noise-free text object—perfectly prepared for chunking, embedding, and vector storage.
3. Chunking for Efficient RAG Inference
Large Language Models work best with well-structured, context-rich text segments rather than long, unbounded documents. Jira issues, especially those with long descriptions, diagnostic logs, or lengthy comment threads, can easily exceed optimal token limits.
Chunking ensures every piece of information is broken down into manageable, meaningful 300–500 token segments that maximize retrieval accuracy and LLM performance.
Why Chunking Matters
- Prevents token overload: LLMs perform poorly when fed oversized text blobs.
- Improves semantic search: Smaller segments produce more precise embeddings.
- Increases relevance: Each chunk represents a focused idea, making retrieval more accurate.
- Speeds up inference: Less text → faster embedding, retrieval, and generation.
How NiFi Performs Chunking:
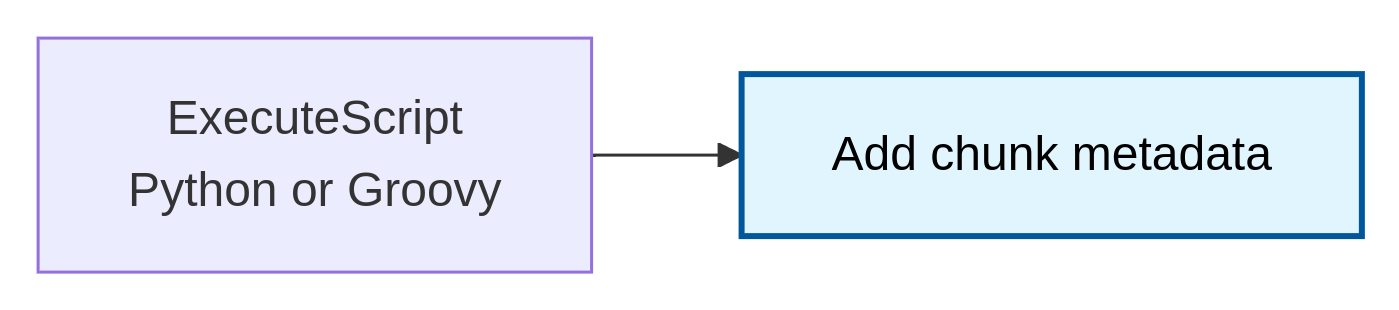
Each chunk is enriched with key identifiers such as:
- Issue key (e.g., SUPPORT-241)
- Project name
- Components and labels
- Resolution date
- Chunk index (e.g., chunk 1 of 4)
4. Generating Embeddings Using LLM Providers
Once your Jira ticket text is cleaned and chunked, the next step is transforming each segment into a numerical vector representation—an embedding. These embeddings allow your RAG pipeline to perform semantic search, retrieve relevant historical issues, and ground LLM responses in accurate support knowledge.
Apache NiFi 2.x makes this stage seamless by orchestrating calls to any embedding provider – cloud, on-prem, or open-source.
How NiFi Handles Embedding Generation

Supported Embedding Providers
You can use:
- OpenAI (text-embedding-3-large, text-embedding-3-small)
- NVIDIA NIM embedding models
- Hugging Face / Local Models
- Cohere
- Custom internal embedding services
Now, every chunk of your Jira ticket data is enriched with a high-quality embedding vector. This creates the foundation for accurate semantic search and ensures your RAG system can surface the most relevant historical issues every time.
5. Storing Embeddings in a Vector Database
Once embeddings are generated, they must be stored in a system optimized for semantic search. Traditional databases are not built to understand vector similarity—so RAG pipelines rely on vector databases that can perform fast, accurate nearest-neighbor searches.
Apache NiFi 2.x makes this step seamless by orchestrating upsert operations to your preferred vector store using simple, configurable REST calls.
Why a Vector Database Is Essential
A vector database enables your support assistant to:
- Retrieve similar historical issues, even if phrasing differs.
- Search across multiple fields (description, comments, resolutions).
- Rank results by semantic relevance.
- Scale to millions of embeddings without losing performance.
Supported Vector Databases
Your NiFi pipeline can push embeddings into any modern vector DB, including:
- Pinecone – fully managed, enterprise-grade.
- Milvus – high-performance open-source vector store.
- Chroma DB – lightweight and developer-friendly.
- Weaviate – modular, cloud or self-hosted.
How NiFi Handles Vector Storage

By the end of this stage, your entire Jira history – cleaned, chunked, and vectorized – is indexed inside a high-performance vector database.
This becomes the backbone of your semantic retrieval layer, enabling your RAG system to instantly surface the most relevant past issues for any user query.
6. Semantic Retrieval Workflow
When a user submits a support query (via UI or API), NiFi orchestrates a lightweight semantic search pipeline to return the most relevant past cases:
Flow:

How it works:
- HandleHttpRequest: Captures the user’s natural-language question.
- Query Embedding: The text is sent to the embedding service to generate a vector representation.
- Vector Search: NiFi passes the embedding to the vector database, which performs semantic similarity search.
Result:
The pipeline returns the top-matching Jira tickets, troubleshooting guides, and documentation snippets, ranked by contextual relevance.
7. LLM Response Generation
Once the top semantic matches are retrieved, NiFi triggers the final step – LLM synthesis to convert raw context into a clear, actionable answer.

How it works:
- Context Packaging: The retrieved Jira tickets, guides, and engineering notes are structured into a clean context bundle.
- InvokeHTTP (LLM Completion): NiFi sends this context along with the user’s original query to the LLM endpoint (OpenAI, Anthropic, etc.).
- Grounded Response Generation: The LLM analyzes both the query and supporting evidence to generate a precise, step-by-step answer—grounded in historical cases and internal documentation.
- HandleHttpResponse: The final, well-structured support response is delivered back to the UI or API client.
Result:
Users receive accurate, context-rich answers instantly, powered by organizational knowledge and LLM reasoning. This reduces ticket resolution time and enables smoother cross-team collaboration.
How Data Flow Manager Accelerates RAG Pipeline Development
Building a production-grade RAG pipeline on Apache NiFi 2.x typically requires significant engineering effort:
- Designing flows
- Writing processors
- Managing vector databases
- Configuring LLM endpoints
- Continuously monitoring the system
This complexity slows down delivery and increases operational overhead.
Data Flow Manager (DFM) eliminates these challenges and dramatically accelerates RAG adoption.
Pre-Built RAG Pipelines & Templates
DFM ships with a rich library of ready-to-deploy RAG blueprints purpose-built for NiFi 2.x, including:
- Pre-configured RAG pipeline templates.
- Jira Customer Support RAG solution packs.
- Document ingestion, parsing & chunking flows.
- Native integrations with Pinecone, Milvus, Chroma, and Weaviate.
- Query → Retrieval → LLM Generation orchestration templates.
With these components, teams can assemble and launch a complete RAG pipeline in minutes instead of weeks, without writing custom processors or scripts.
Result: Faster experimentation, faster iterations, and faster time-to-value.
Agentic AI-Powered NiFi Operations – Fully Managed via UI
DFM includes an advanced NiFi Ops Manager that automates every layer of platform lifecycle:
- Zero-touch cluster provisioning.
- One-click NiFi upgrades & patches.
- Seamless flow deployments across environments.
- Real-time monitoring, KPIs, and alerting.
- AI-driven bottleneck detection & auto-remediation.
- Built-in governance, logging & audit trails.
This ensures your RAG workloads run reliably, securely, and at enterprise scale without manual babysitting or deep NiFi expertise.
In short, DFM transforms NiFi into a plug-and-play RAG platform, empowering engineering, support, and data teams to ship intelligent retrieval workflows with unmatched speed and operational confidence.
Conclusion
Apache NiFi 2.x, when paired with a robust RAG architecture, fundamentally elevates how enterprises access and deliver support knowledge. By unifying Jira tickets, documentation, and engineering notes into an intelligent retrieval system powered by embeddings, vector search, and LLM reasoning, organizations can drastically cut resolution times and lighten the load on L1/L2 teams.
With Ksolves’ Data Flow Manager, this transformation becomes even faster and more scalable. DFM enables teams to deploy production-ready RAG pipelines in minutes and operate them effortlessly through an AI-driven NiFi Ops Manager. It ensures reliability, governance, and continuous optimization.
![]()
